GWRL - A high performance event reactor and proactor written in C.
GWRL is an event loop - you create and register input sources that can post events, like file IO events and time events. The event loop manages those input sources, gathers events from them and notifies you of those events. At it's core a reactor polls for events and notifies you about them. It has an optional proactor interface to create a unified cross-platform API for Unix and Windows.
This document explains as much as possible about GWRL - how to use it, and how it works. If you have suggestions, comments, spelling corrections, or gramar nazi corrections you can email me at gngrwzrd@gmail.com. But please don't email me for technical support.
libgwrl is Copyright 2012 by Aaron Smith (gngrwzrd@gmail.com)
-You are free to modify for private studying.
-You are free to use in commercial software.
-You are free to re-distribute modified versions of the source.
-You are free to derive or fork other versions of the source.
-You are not free to re-distribute source or object libraries under a different license.
If you release a modified, derived, or forked version, the author Aaron Smith must be notified by email at gngrwzrd@gmail.com. The new version must contain the LICENSE file - you can rename it to GWRL_LICENSE if needed.
Commercial and non-commercial executable software must contain the above copyright notice in a user accessible window, help, or about notice.
Aaron Smith is not liable for damage resulting from this code.
GWRL uses CMake to generate native makefiles and workspaces that can be used in the compiler environment of your choice. Get it at http://cmake.org/.
If you're new to CMake there's a lot of documentation on their site, and it's worth mentioning this video series on Youtube for beginners: http://www.youtube.com/watch?v=CLvZTyji_Uw
I'm not able to test on every operating system and compiler. These are the ones that I have at my disposal and have tested examples on.
Operating Systems:
Compilers and Workspaces:
If a particular operating system or compiler isn't listed here, give it a shot anyway - either it'll work or it wont. If you know enough about C and are willing to try and add support for your platform or compiler, it'd be something worth contributing to GWRL.
I'm willing to help get GWRL compiling on other systems, you'd have to dedicate some resources on a server over SSH with git and compiler installed. I won't drop everything to add support for a target operating system or compiler though - when I get free time I would, unless you want to pay me.
This is just a quick example of generating a makefile - because CMake supports so many generators you can read CMake docs for more information. Here's how to generate a Makefile on Linux or Mac:
cd libgwrl mkdir build; cd build cmake .. make
By default CMake is configured to create a static .a archive and a dyld for Linux and Max. Windows will create a .lib file and .dll.
Reactor and Proactor are design patterns which you can find resources about on google. They're worth describing briefly here because GWRL is built with these two patterns.
Reactor is a pattern that notifies you about events being ready - relying on you to react to the event. An example file IO event is a read ready event - you're notified from the kernel that a read is ready and would complete successfully, but it's up to you to initiate it.
Proactor is a pattern that notifies you about events being completed, passing data back to you. An example file IO event is a read complete event - you're notified from the kernel that a read completed and would pass you a buffer with that data for you to use.
On Unix, kernel event polling mechanisms are reactor based. On Windows, kernel event polling mechanisms are proactor based.
GWRL was built with the reactor and proactor patterns in mind. Because the kernel event polling mechanisms are so different on Unix and Windows, it was a natural fit to build it this way.
The reactor implements all kernel synchronous polling mechanisms, including Windows IO Completion Ports. The reactor by itself is usable on Unix operating systems, but would be more work to use by itself on Windows - you'd need to write more code to maintain cross platform compatibility with Windows. The proactor however makes it easy to use a single API for cross platform compatibility.
The proactor decorates the reactor as a an API that uses the reactor internally. On Unix, the proactor performs all IO operations on your behalf and notifies you when they've completed. On Windows, the proactor calls Windows functions that support overlapped IO and notify you when they've completed.
Building GWRL this way created a unified proactor API supported on Unix and Windows.
The reactor is the core to gwrl - it manages all input sources, event dispatching, event gathering, and synchronous kernel polling. This section describes as much as possible about it.
The reactor is not intended to be used on Windows by itself. You should read documentation about the reactor as most of the API's are still used on Windows, just not file input sources which you'll read about shortly.
You create a reactor with:
gwrl * gwrl_create();
You run the reactor with one of these:
void gwrl_run_once(gwrl * rl); void gwrl_run(gwrl * rl);
If you use gwrl_run() the reactor will run indefinitely until it's stopped.
You can stop the reactor with:
void gwrl_stop(gwrl * rl);
A backend is the logic that implements the synchronous kernel polling function selected at compile time - for example kqueue. Each backend is in a separate C file. Only one can be included at compile time.
Each backend will cause the current thread to sleep until an event is received from the kernel, or a timeout occurs. This behavior can be shut off so that the backend will not put the thread to sleep.
Disable backend sleeping with this:
void gwrl_allow_poll_sleep(gwrl * rl, int onoff);
Input sources are the objects that the reactor can gather events from - like file IO events, or time events. Time input sources can be timeouts, intervals, or future date timeouts.
Timeouts are specified in milliseconds.
Timeout input sources can be persistently installed with the reactor; if a timeout expires it will remain installed so you can re-arm it later without having to re-create and re-install another similar timeout.
You can use the userdata parameter to pass any opaque user data to keep associated with the input source. The user data will get passed back to you when any events occur.
You create a timeout input source with either of these:
//create and register a timeout input source gwrlsrc * gwrl_set_timeout(gwrl * rl, int64_t ms, bool persist, gwrlevt_cb * cb, void * userdata); //create a time input source that you must register manually gwrlsrc * gwrl_src_time_create(int64_t ms, bool repeat, int whence, bool persist, gwrlevt_cb * callback, void * userdata);
Example:
#include "gwrl/event.h"
void timeout1(gwrl * rl, gwrlevt * evt) {
//re-arm the timeout
gwrl_src_enable(rl,evt->src);
}
void timeout2(gwrl * rl, gwrlevt * evt) {
}
int main(int argc, char ** argv) {
gwrl * rl = gwrl_create();
//create a persistent timeout which can be re-armed
gwrlsrc * timeout1 = gwrl_set_timeout(rl,1000,true,&my_callback,NULL);
//create another timeout that isn't persistent.
gwrlsrc * timeout2 = gwrl_src_time_create(3000,false,GWRL_NOW,false,&timeout2,NULL);
gwrl_src_add(rl,timeout2);
return 0;
}
You can delete all expired, persistant timeout input sources with this:
void gwrl_del_persistent_timeouts(gwrl * rl);
Intervals are specified in milliseconds.
You can use the userdata parameter to pass any opaque user data to keep associated with the input source. The user data will get passed back to you when any events occur for this input source.
You create an interval input source with any of these:
//create and register a repeating interval input source gwrlsrc * gwrl_set_interval(gwrl * rl, int64_t ms, gwrlevt_cb * callback, void * userdata); //create a time input source that you must register manually gwrlsrc * gwrl_src_time_create(int64_t ms, bool repeat, int whence, bool persist, gwrlevt_cb * callback, void * userdata);
Examples:
#include "gwrl/event.h"
void interval1(gwrl * rl, gwrlevt * evt) {
}
void interval2(gwrl * rl, gwrlevt * evt) {
}
int main(int argc, char ** argv) {
gwrl * rl = gwrl_create();
gwrlsrc * interval1 = gwrl_set_interval(rl,1000,&interval1,NULL);
gwrlsrc * interval2 = gwrl_src_time_create(1250,true,GWRL_NOW,false,&interval2,NULL);
gwrl_src_add(rl,interval2);
gwrl_run(rl);
return 0;
}
Future date timeouts are timeouts that happen at an absolute future time specified in milliseconds.
You can use the userdata parameter to pass any opaque user data to keep associated with the input source. The user data will get passed back to you when any events occur for this input source.
Create a future date timeout with any of these:
//create and register a future date timeout gwrlsrc * gwrl_set_date_timeout(gwrl * rl, int64_t ms, gwrlevt_cb * cb, void * userdata); //create a time input source that you must register manually gwrlsrc * gwrl_src_time_create(int64_t ms, bool repeat, int whence, bool persist, gwrlevt_cb * callback, void * userdata);
Example:
#include "gwrl/event.h"
void day_later(gwrl * rl, gwrlevt * evt) {
}
void day2_later(gwrl * rl, gwrlevt * evt) {
}
int main(int argc,c har ** argv) {
gwrl * rl = gwrl_create();
int64_t ms = 0;
struct timespec ts;
gwtm_gettimeofday_timespec(&ts);
gwtm_timespec_to_ms(&ts,&ms);
ms += 86400000;
gwrlsrc * timeout1 = gwrl_set_date_timeout(rl,ms,&day_later,NULL);
ms += 86400000;
gwrlsrc * timeou2 = gwrl_src_time_create(ms,false,GWRL_ABS,false,&day2_later,NULL);
gwrl_src_add(rl,timeout2);
gwrl_run(rl);
return 0;
}
File input sources can generate read and write events. The interest flags you use to indicate which events you want to be notified about are GWRL_RD | GWRL_WR.
Create a file input source with either of these:
//create and register a file input source gwrlsrc * gwrl_set_fd(gwrl * rl, fileid_t fd, uint16_t flags, gwrlevt_cb * cb, void * userdata); //create a file input source that you must register manually gwrlsrc * gwrl_src_file_create(fileid_t fd, uint16_t flags, gwrlevt_cb * callback, void * userdata);
Example:
void stdin_activity(gwrl * rl, gwrlevt * evt) {
if(evt->flags & GWRL_RD) {
char buf[1024];
read(evt->fd,buf,sizeof(buf));
}
}
int main(int argc, char ** argv) {
gwrl * rl = gwrl_create();
gwrl_set_fd(rl,STDIN_FILENO,GWRL_RD,&stdin_activity,NULL);
gwrl_run(rl);
}
Unfortunately because each kernel event polling function is so different, it's difficult to provide detailed error codes at all times to GWRL library users. When GWRL encounters an error associated with a file descriptor, it will post a GWRL_RD event to propogate the error back to you. When you finally read from that file descriptor, you can rely on the return value to figure out what has happened with the file descriptor.
Example:
void stdin_activity(gwrl * rl, gwrlevt * evt) {
if(evt->flags & GWRL_RD) {
//detect errors here with a read.
}
}
int main(int argc, char ** argv) {
gwrl * rl = gwrl_create();
gwrlsrc * stdinsrc = gwrl_set_fd(rl,STDIN_FILENO,GWRL_RD,stdin_activity,NULL);
gwrl_run(rl);
}
If you created an input source with any functions that don't automatically add it to the reactor, you can use this function:
//add any input source void gwrl_src_add(gwrl * rl, gwrlsrc * src);
Input sources can be disabled, enabled, removed, or deleted at any time.
//disable an input source void gwrl_src_disable(gwrl * rl, gwrlsrc * src); //re-enable an input source, or re-arm a persistent timeout source void gwrl_src_enable(gwrl * rl, gwrlsrc * src); //remove an input source but don't free it void gwrl_src_remove(gwrl * rl, gwrlsrc * src); //remove and free an input source, the prev parameter should be NULL //unless you know what it's used for. void gwrl_src_del(gwrl * rl, gwrlsrc * src, gwrlsrc * prev, bool freesrc);
Input sources contain a custom tag property that you can use at any time to identify an input source.
Example:
gwrlsrc * src = gwrl_set_fd(rl,STDIN_FILENO,GWRL_RD,&didrd,NULL); src->tag = MY_IDENTIFIER;
This is useful in callbacks or with the gwrl_free function described below.
All reactor callbacks use this function prototype:
typedef void (gwrlevt_cb)(struct gwrl * rl, struct gwrlevt * evt);
For any event that the reactor dispatches, it passes you a gwrlevt object that contains more information about the event:
typedef struct gwrlevt {
uint16_t flags; //interest flags GWRL_RD, GWRL_WR
fileid_t fd; //file descriptor
void * userdata; //opaque user data for users of the API
//gwrlsrc that generated the event, can be NULL.
//src->fd is the same as fd above.
struct gwrlsrc * src;
} gwrlevt;
Not every field is needed at all times. For example a custom function call event (below) wouldn't have a valid src set because it technically didn't come from a valid source.
You can create and post events at any time. Create an event with this:
gwrlevt * gwrl_evt_create(gwrl * rl, gwrlsrc * src, gwrlevt_cb * callback, fileid_t fd, gwrlevt_flags_t flags);
Only rl and callback is required.
After you've created an event, post it with:
void gwrl_post_evt(gwrl * rl, gwrlevt * evt);
A function call event can be posted to the reactor for immediate dispatching on the next iteration. The event that gets dispatched will not contain a src object because no input source technically generated the event.
Post a function call event with:
void gwrl_post_function(gwrl * rl, gwrlevt_cb * cb, void * userdata);
Example:
#include "gwrl/event.h"
void setup(gwrl * rl, gwrlevt * evt) {
printf("function called!\n");
}
int main(int argc, char ** argv) {
gwrl * rl = gwrl_create();
gwrl_post_function(rl,&setup,NULL);
gwrl_run(rl);
}
Internally the reactor runs through four different phases on each iteration of the reactor loop.
The dispatch events phase calls the callbacks of all gathered events from the previous iteration of the reactor loop. If more events are posted during the dispatch phase, those will also be dispatched, but re-dispatching will only happen at a maximum of five times. If more events were posted during the re-dispatch phase they will not be dipatched until the next loop iteration.
This phase gathers time events from all time input sources and appends any found events to the dispatch queue to dispatch on the next loop iteration. It also finds and stores the shortest period of time before a time event will occur. That time period is used as a timeout value for the event IO backend.
This phase uses the compiled backend to wait for events from the kernel to be ready. If no events are ready the thread is put to sleep until events are ready or a timeout occurs, whichever happens first. Event backend sleeping can be shut off, refer to backend sleeping above.
The fourth and final phase is to call user-supplied event gathering functions. This can be used to extend the reactor with custom input sources and custom gathering phases for those input sources.
This flowchart illustrates how the reactor event loop runs internally which may help explain the reactor phases a bit more.
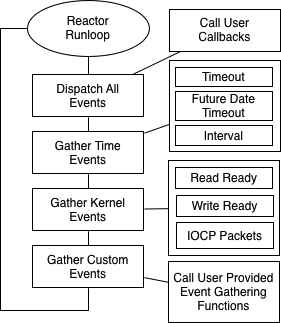
Users of GWRL can create custom input sources to register with the reactor. At compile time you'll need to increase the GWRL_SRC_TYPES_COUNT option. By default this is set to 2, the reactor supports two input source types - file and time. You'll need increase it by how ever many input sources you're adding.
Custom input sources must specify a type that doesn't conflict with existing types. The type is an integer, currently 0 and 1 is taken by file and time. So your input sources would need to start at 2.
Example:
#define MY_INPUT_SRC_TYPE 2
typedef struct my_input_src {
gwrlsrc _; //inherit required input source structure
int something;
int something_else;
} my_input_src;
int main(int argc, char ** argv) {
gwrl * rl = gwrl_create();
my_input_src * mis = calloc(1,sizeof(my_input_src));
gwrlsrc * src = (gwrlsrc *)mis;
src->type = MY_INPUT_SRC_TYPE;
gwrl_src_add(rl,src);
gwrl_run(rl);
return;
}
Users of GWRL can create their own event gathering functions. These functions get called on every loop iteration for you to poll for any events that need to be posted.
Example:
#include "gwrl/event.h"
#define MY_SOURCE_TYPE 2
typedef struct my_source {
gwrlsrc _;
int something;
} my_source;
void my_gather(gwrl * rl) {
gwrlsrc * src = rl->sources[MY_SOURCE_TYPE];
my_source * msrc = NULL;
while(src) {
msrc = (my_source *)src;
msrc->something++;
if(msrc->something == 10) {
msrc->something = 0;
gwrlevt * evt = gwrl_evt_create(rl,src,src->callback,src->userdata,0,0);
gwrl_post_evt(rl,evt);
}
src = src->next;
}
}
void my_callback(gwrl * rl, gwrlevt * evt) {
//printf("custom gather fired an event for a custom input source.\n");
gwrl_stop(rl);
}
int main(int argc, char ** argv) {
gwrl * rl = gwrl_create();
my_source * msrc = gwrl_mem_calloc(1,sizeof(my_source));
gwrlsrc * src = _gwrlsrc(msrc);
msrc->something = 0;
src->type = MY_SOURCE_TYPE;
src->callback = &my_callback;
gwrl_add_gather_fnc(rl,&my_gather);
gwrl_allow_poll_sleep(rl,0);
gwrl_src_add(rl,src);
gwrl_run(rl);
return 0;
}
Freeing a reactor can be quick or more involved, depending on how you want to handle the input sources that the reactor is currently monitoring.
You free a reactor with this:
void gwrl_free(gwrl * rl, gwrlsrc ** sources);
The sources parameter can be handled in two ways. Either NULL, which tells the reactor to free all input source objects - this does not free resources like user data or file descriptors though.
Or, if you provide a pointer, all internal input sources are linked together in a linked list for you to loop over and dispose of file descriptors and user data. This gives you a mechanism to control which file descriptors you want closed or user data pointers you want freed.
The "rl" parameter can be NULL - this can be used to free the list of gwrlsrc objects on your behalf - after you've disposed of file descriptors or userdata.
You can use Input Source Tagging described earlier in order to help you decide what to do with an input source.
Example:
void did_read(gwrl * rl, gwrlevt * evt) {
}
int main(int argc, char ** argv) {
gwrl * rl = gwrl_create();
gwrl_set_fd(rl,STDIN_FILENO,GWRL_RD,&didrd,NULL);
gwrlsrc * sources = NULL;
gwrlsrc_file * fsrc = NULL;
gwrl_free(rl,&sources);
while(sources) {
fsrc = (gwrlsrc_file *)sources;
//possibly use source->tag to switch on something.
if(sources->type == GWRL_SRC_TYPE_FILE) {
//close descriptor if needed
close(fsrc->fd);
}
sources = sources->next;
}
gwrl_free(NULL,&sources);
return 0;
}
It is difficult for GWRL to decide what to free and when. Providing an interface like this provides the simplest API for GWRL, and more flexibility for the user.
There are some cmake compile time options you can use to control some internal mechanisms that may effect performance.
This is the number of gwrlevt structures to keep in a cache list which can be re-used when a new gwrlevt is needed. If any exist in cache then that will be used. If the number of gwrlevt objects in cache exceeds this maximum amount, then they are freed rather than cached. The default is 128.
The number of events to accept from epoll_wait. This does not grow internally as more input sources are added. The default is 64.
The maximum number of user provided gather functions. Refer back to Custom Event Gathering section for more information. The default is 0.
The number of events to accept from kevent. This does not grow internally as more input sources are added. The default is 64.
The initial number of file descriptors that poll can monitor. If more input sources are added to poll the size will grow by a factor of this number. The default is 64.
The number of supported input sources. Currently 2. Refer back to Custom Input Sources for more information.
At times you may want one reactor to use the default compile time options, but then override them on another reactor to control it differently.
Example:
gwrl * rl = gwrl_create(); gwrl_options opts = GWRL_DEFAULT_OPTIONS; opts.gwrl_event_cache_max = 1024; gwrl_set_options(rl,&opts);
Overridable Properties:
typedef struct gwrl_options {
int gwrl_event_cache_max;
int gwrl_gather_funcs_max;
int gwrl_kqueue_kevent_count;
int gwrl_epoll_event_count;
int gwrl_pollfd_count;
} gwrl_options;
The proactor is an interface built on top of the reactor, and actually uses the reactor internally. Instead of receiving callbacks when an IO operation is ready or can complete successfully, the IO operation is done for you internally and you're notified when it's completed.
When working with a proactor, you still use most of the reactor API's with the exception of file IO input sources - Those must be added with the proactor API.
When you create a proactor you need to supply it with a reactor which will dispatch the proactor with events.
Example:
gwrl * rl = gwrl_create(); gwpr * pr = gwpr_create(rl);
Any file input sources you're using will need to be registered through the proactor interface, instead of the reactor interface.
You can register them with:
//shortcut for gwpr_src_add gwrlsrc_file * gwpr_set_fd(gwpr * pr, fileid_t fd, void * userdata); //add a file input source void gwpr_src_add(gwpr * pr, gwrlsrc_file * fsrc);
Example:
int main(int argc, char ** argv) {
gwrl * rl = gwrl_create();
gwpr * pr = gwpr_create(pr);
gwrlsrc_file * src = gwpr_set_fd(pr,STDIN_FILENO,NULL);
gwrl_run(rl);
}
File input sources can have callbacks associated with the completed IO operations that you initiate.
Set a callback with:
void gwpr_set_cb(gwpr * pr, gwrlsrc_file * fsrc, gwpr_cb_id cbid, void * cb);
This associates a callback with the file input source. You can control which operation's callback is being set with the cbid parameter. It supports these callback id's:
typedef enum gwpr_cb_id {
gwpr_error_cb_id,
gwpr_accept_cb_id,
gwpr_connect_cb_id,
gwpr_closed_cb_id,
gwpr_did_read_cb_id,
gwpr_did_write_cb_id,
} gwpr_cb_id;
Example:
void did_read(gwpr * pr, gwpr_io_info * info) {
}
int main(int argc, char ** argv) {
gwrl * rl = gwrl_create();
gwpr * pr = gwpr_create(pr);
gwrlsrc_file * stdin_src = gwpr_set_fd(pr,STDIN_FILENO,NULL);
gwpr_set_cb(pr,stdin_src,gwpr_did_read_cb_id,&did_read);
gwrl_run(rl);
}
When a callback is called for a read or write operation, you can use the "op" member of the gwpr_io_info structure to inspect which function actually performed the operation.
Example:
void did_read(gwpr * pr, gwpr_io_info * info) {
if(info->op == gwpr_read_op_id) {
//tcp or regular file read
} else if(info->op == gwpr_recvfrom_op_id) {
//udp
}
}
Here are all the supported operation ids you'll encounter:
typedef enum gwpr_io_op_id {
gwpr_read_op_id,
gwpr_recv_op_id,
gwpr_recvfrom_op_id,
gwpr_recvmsg_op_id,
gwpr_write_op_id,
gwpr_send_op_id,
gwpr_sendto_op_id,
gwpr_sendmsg_op_id,
} gwpr_io_op_id;
The proactor uses buffer objects for reading and writing data on your behalf. You are always responsible for freeing buffers when you don't need them anymore.
The proactor will create buffers internally and pass them to your callbacks, you are still responsible for freeing them.
You can get a buffer with:
gwprbuf * gwpr_buf_get(gwpr * pr, size_t size); gwprbuf * gwpr_buf_get_tagged(gwpr * pr, size_t size, int tag);
You can free a buffer with:
void gwpr_buf_free(gwpr * pr, gwprbuf * buf);
You can use the buffer directly in your callback methods. These are the public structure members you have at your disposal:
//buffer for IO operations
typedef struct gwprbuf {
int tag;
size_t len;
size_t bufsize;
char * buf;
} gwprbuf;
Some other utility buffer methods exist:
ssize_t gwpr_buf_cpyin(gwprbuf * to, char * from, size_t len); ssize_t gwpr_buf_cpyout(gwprbuf * from, char * to, size_t len); ssize_t gwpr_buf_cpy(gwprbuf * to, gwprbuf * from, size_t len);
Each gwprbuf object contains a "tag" member you can use at your disposal.
A contrived example:
#define FROM_STDIN 1
void didrd(gwpr * pr, gwpr_io_info * info) {
if(info->buf->tag == FROM_STDIN) {
//data was from stdin
}
}
int main(int argc, char ** argv) {
gwrl * rl = gwrl_create();
gwpr * pr = gwpr_create(rl);
gwrlsrc_file * stdin_src = gwpr_set_fd(pr,STDIN_FILENO,NULL);
gwpr_set_cb(pr,stdin_src,gwpr_did_read_cb_id,&didrd);
gwpr_read(pr,stdin_src,gwpr_buf_get_tagged(pr,128,FROM_STDIN));
gwrl_run(rl);
}
On Unix, initiating a read tells the event backend to wait for a readable event. When the file descriptor is readable, the proactor will read for you and call your callback with the data and more information.
On Windows, initiating a read calls the Windows function that implements overlapped IO. Once that's completed the proactor will call your callback with the data and more information.
Initiate a read with any of these:
gwpr_read(gwpr * pr, gwsrc_file * fsrc, gwprbuf * buf); gwpr_recv(gwpr * pr, gwrlsrc_file * fsrc, gwprbuf * buf); gwpr_recvfrom(gwpr * pr, gwrlsrc_file * fsrc, gwprbuf * buf); gwpr_recvmsg(gwpr * pr, gwrlsrc_file * fsrc, gwprbuf * buf);
Any of those will intitiate a read, and upon completion call the gwpr_did_read_cb_id callback. The buffer provided should be a buffter from gwpr_buf_get, or a buffer you know you don't need anymore.
Example:
void did_read(gwpr * pr, gwpr_io_info * info) {
gwpr_buf_free(info->buf);
}
int main(int argc, char ** argv) {
gwrl * rl = gwrl_create();
gwpr * pr = gwpr_create(rl);
gwrlsrc_file * src = gwpr_set_fd(pr,STDIN_FILENO,NULL);
gwpr_set_cb(pr,src,gwpr_did_read_cb_id,&did_read);
gwpr_read(pr,src,gwpr_buf_get(pr,128));
gwrl_run(rl);
}
When the proactor reads data or receives data from Windows IOCP, it will call any read filters you've attached to the file input source. This can be useful for modifying the data before the gwpr_did_read_cb_id is called.
Add a filter with this:
void gwpr_filter_add(gwpr * pr, gwrlsrc_file * fsrc, gwpr_filter_id fid, gwpr_io_cb * fnc);
Reset the filters with this:
void gwpr_filter_reset(gwpr * pr, gwrlsrc_file * fsrc, gwpr_filter_id fid);
The filter API is limited to these two functions to reduce the internal logic to support them. Therefore you can only add or reset them. If you ever needed to re-order the filters you'd have to reset and re-add all filters.
Example:
void my_read_filter(gwpr * pr, gwpr_io_info * info) {
printf("1. called read filter!\n");
char * buf = info->buf->buf;
//do something to buf..
//reset info->buf->len
}
void my_did_read(gwpr * pr, gwpr_io_info * info) {
printf("2. called read cb\n");
}
int main(int argc, char ** argv) {
gwrl * rl = gwrl_create();
gwpr * pr = gwpr_create(rl);
gwrlsrc_file * stdin_src = gwpr_set_fd(pr,STDIN_FILENO,NULL);
gwpr_set_cb(pr,stdin_src,gwpr_did_read_cb_id,&my_did_read);
gwpr_filter_add(pr,stdin_src,gwpr_rdfilter_id,&my_read_filter);
gwpr_read(pr,stdin_src,gwprbuf_get(pr,1024));
gwrl_run(rl);
return 0;
}
Each file input source registered with the proactor can have it's own error callback set for read and write error reporting. Refer back to the Callbacks section and use gwrl_error_cb_id to set your error callback.
When a read error occurs in the proactor there are a few cases that can take place. This section describes those errors.
On Unix, when a read is attempted on a socket or a file descriptor, the proactor will check for EOF, which on a socket indicates a disconnected state,for a regular file means there's nothing left to read, for a pipe means the other end of the pipe isn't connected.
On Windows, the result of an overlapped read indicates socket closure or EOF. Pipes on Windows aren't used in GWRL.
This specific case has it's own callback you can use - refer back to the Callbacks section and use the gwrl_closed_cb_id to set a closed callback.
On Unix, these two errors indicate the the socket or file descriptor is set for non-blocking IO, but calling read would block. The proactor handles this internally and simply does nothing. If the reactor backend is monitoring the input source for reads then the proactor will run again when it's readable with more data.
On Unix, initiating a write tells the event backend to wait for the file descriptor to be writable. When that descriptor is writable the data is written for you and your callback is called with more information.
On Windows, initiating a write calls the Windows function that implements overlapped IO. Once that's completed the proactor will call your callback with the data and more information.
Initiate a write with any of these:
gwpr_write(gwpr * pr, gwsrlsrc_file * fsrc, gwprbuf * buf); gwpr_send(gwpr * pr, gwrlsrc_file * fsrc, gwprbuf * buf); gwpr_sendto(gwpr * pr, gwrlsrc_file * fsrc, gwprbuf * buf, struct sockaddr_storage * addr, socklen_t socklen); gwpr_sendmsg(gwpr * pr, gwrlsrc_file * fsrc, gwprbuf * buf);
Any of those will initiate a write, and upon completion call the gwpr_did_write_cb_id callback.
Example:
gwrlsrc_file * stdin_src;
gwrlsrc_file * stdout_src;
void did_write(gwpr * pr, gwpr_io_info * info) {
gwpr_buf_free(pr,info->buf);
}
void did_read(gwpr * pr, gwpr_io_info * info) {
gwpr_write(pr,stdout_src,info->buf);
}
int main(int argc, char ** argv) {
gwrl * rl = gwrl_create();
gwpr * pr = gwpr_create(rl);
stdin_src = gwpr_set_fd(pr,STDIN_FILENO,NULL);
stdout_src = gwpr_set_fd(pr,STDOUT_FILENO,NULL);
gwpr_set_cb(pr,stdin_src,gwpr_did_read_cb_id,&did_read);
gwpr_set_cb(pr,stdout_src,gwpr_did_write_cb_id,&did_write);
gwpr_read(pr,stdin_src,gwpr_buf_get(pr,128));
gwrl_run(rl);
return 0;
}
When the proactor is going to write data on your behalf, it will first call write filters which allows you to alter the buffer data somehow before it's written.
Example:
gwprsrc_file * stdin_src;
gwprsrc_file * stdout_src;
void my_did_read(gwpr * pr, gwpr_io_info * info) {
printf("1. called did read cb\n");
gwpr_write(pr,stdout_src,info->buf);
}
void my_write_filter(gwpr * pr, gwpr_io_info * info) {
printf("2. called write filter!\n");
char * buf = info->buf->buf;
//do something to buf.
}
void my_did_write(gwpr * pr, gwpr_io_info * info) {
printf("3. called did write callback\n");
}
int main(int argc, char ** argv) {
gwrl * rl = gwrl_create();
gwpr * pr = gwpr_create(rl);
stdin_src = gwpr_set_fd(pr,STDIN_FILENO,NULL);
stdout_src = gwpr_set_fd(pr,STDOUT_FILENO,NULL);
gwpr_set_cb(pr,stdout_src,gwpr_did_write_cb_id,&my_did_write);
gwpr_set_cb(pr,stdin_src,gwpr_did_read_cb_id,&my_did_read);
gwpr_filter_add(pr,stdout_src,gwpr_wrfilter_id,&my_write_filter);
gwpr_read(pr,stdin_src,gwprbuf_get(pr,1024));
gwrl_run(rl);
return 0;
}
It is possible for the proactor to perform partial writes - meaning not all of the data you wanted written was written. If this happens the proactor updates the write queue to write starting where it left off, and wait for the file descriptor to be writable again.
The buffer you receive in the callback will only contain the data that was actually written.
On Unix operating systems, if you're using synchronous reactor backends like kqueue, epoll, select, etc, the proactor tries to mimic asynchronous behavior by telling the reactor backend that you intend to write to a descriptor - when that file descriptor is writable, the data is written on your behalf.
This however has performance implications with backends like kqueue or epoll since those are system calls. It can also lead to unneccessary function calls because most of the time the descriptor will be writable immediately. For this case specifically, the proactor supports trying synchronous writes immediately when they're requested. This can be enabled or disabled at compile time. It also supports setting a threshold for maximum bytes to try synchronous writes with.
If a synchronous write succeeds, your did_write callback will be called asynchronously on the next reactor loop iteration.
If a synchronous write is a partial write, your did_write callback is called and the remaining data is put on the write queue for later when the file descriptor is writable.
If a synchronous write fails, it's placed on the write queue for that file when the descriptor is writable again.
See the Proactor CMake Compile-Time Options section for configuration compile time options for this feature.
Something to keep in mind when using the synchronous write attempts on Unix is that if your file descriptor is not nset as non-blocking, this method will block indefinitely. Your descriptors should always be non-blocking before using this functionality.
The proactor will detect and notify you of write errors, this section describes each write error condition.
If a partial write took place, you're notified first about the data that was successfully written through your did_write callback.
You're then notified about the error with your error callback. The error info object will contain a buffer with the remaining data that couldn't be written.
If no write took place, you're notified about the error with your error callback but no buffer is set.
This specific case has it's own callback you can use - refer back to the Callbacks section and use the gwrl_closed_cb_id to set a closed callback.
If a descriptor reports EWOULDBLOCK or EAGAIN, the descriptor is marked as non-blocking IO and a write would block. The proactor detects this internally and re-queues data for writing.
If a partial write took place, the write queue is updated to start where it left off the next time the descriptor is writable.
The proactor can accept connections on your behalf. When a client is accepted
it will call your callback with the new peer. On Unix accept() is called as
many times as GWPR_MAX_ACCEPT is defined for, or until no connections are pending
to accept.
On Windows, IOCP uses sockets that have to be allocated before calling AcceptEx - meaning GWPR_MAX_ACCEPT sockets will be allocated and a call to AcceptEx is called for each of them. This queues the operation for Windows to accept as many as it can.
You initiate accepting with:
gwpr_accept(gwpr * pr, gwrlsrc_file * fsrc);
Example:
void did_accept(gwpr * pr, gwpr_io_info * info) {
//info->peersrc is a new file input source you can
//do whatever you want with. Note that it isn't registered
//with the proactor. You need to register it yourself with
//a proactor to continue reading and writing with it. It's not
//pre-registered so you can support different threading models.
}
int main(int argc, char ** argv) {
gwrl * rl = gwrl_create();
gwpr * pr = gwpr_create(rl);
sockid_t sock = setup_listening_socket(); //your function
gwrlsrc_file * socksrc = gwpr_set_fd(pr,sock,NULL);
gwpr_set_cb(pr,socksrc,gwpr_accept_cb_ic,&did_accept);
gwpr_accept(pr,socksrc);
gwrl_run(rl);
}
The proactor uses some configurable compile time options that may effect performance.
This option controls the maximum amount of clients to accept. On Unix, this many clients will be accepted or until no clients can be accepted. On Windows, this many sockets will be allocated and calls to AcceptEx are made to queue IO completion ports for Windows to accept clients.
(Unix Only) This controls how many gwprwrq objects are cached for re-use later. When you use any of the write initiating methods, the buffer is placed on a queue for write when the file descriptor is actually writable. The object that goes into queue is the gwprwrq object. Since writes are common, the gwprwrq object will be cached after the write completes for later use. If the number of gwprwrq objects exceeds this option, then they are freed instead of cached.
(Windows Only) This controls how many gwpr_ovlp objects to cache for re-use later. When you use any of the write initiating methods, a gwpr_ovlp object is used and passed to Windows overlapped functions. When that overlapped function completes, the gwpr_ovlp object is cached. If the number of gwpr_ovlp objects in cache exceeds this option, then they're freed instead.
Enable or disable synchronous write trying on Unix.
The maximum bytes allowed to try synchronous writes with.
At times you may want to override the cmake compile time options for one proactor but not another.
Overriding cmake compile-time options:
int main(int argc, char ** argv) {
gwrl * rl = gwrl_create();
gwpr * pr = gwpr_create(rl);
gwpr_options opts = GWPR_DEFAULT_OPTIONS;
opts.gwpr_max_accept = 1024;
gwpr_set_options(pr,&opts);
gwrl_run(rl);
return 0;
}
Overridable Properties:
typedef struct gwpr_options {
int gwpr_max_accept;
int gwpr_wrqueue_cache_max;
int gw_proactor_iocp_ovlp_cache_max;
} gwpr_options;
GWRL allows you to set memory allocation and freeing functions so if you ever wanted to use custom memory allocators you can.
The allocator and free functions used in GWRL are #defines that are replaced with the preprocessor. Currently only calloc, realloc and free are needed. These are the default defines:
#ifndef gwrl_mem_calloc # define gwrl_mem_calloc(n,s) (calloc(n,s)) #endif #ifndef gwrl_mem_free # define gwrl_mem_free(mm) (free(mm)) #endif #ifndef gwrl_mem_realloc # define gwrl_mem_realloc(p,ns) (realloc(p,ns)) #endif
These are used throughout GWRL like this:
gwrl * rl = gwrl_mem_calloc(1,sizeof(gwrl));
You can override these two defines with CMAKE or CCMake.
GWRL does very little memory management for you. This section outlines as much as possible about freeing and non-freeing cases.
These scenarios free data for you.
Non-persistant timeout input sources will be freed for you.
Expired future-date timeouts will be freed for you after they've expired.
If you delete an input source with any of these functions, the input source will be removed and freed.
void gwrl_src_del(gwrl * rl, gwrlsrc * src, gwrlsrc * prev); void gwpr_src_del(gwpr * pr, gwrlsrc_file * fsrc);
It is possible to let the proactor write data for you without a did_write callback. If this happens the write gwprbuf will be freed for you.
These scenarios don't free anything for you.
User data will never be freed for you.
Interval input sources will never be freed for you.
File input sources will never be freed for you.
Anytime you use the proactor you are responsible for any and all gwprbuf objects that come your way, or any that are created by you. There are cases where a read will create a gwprbuf internally and pass it to your did_read callback - you're still responsible for freeing that buffer object at some point.
GWRL is technically not thread-safe, but provides a few thread safe functions when thread safety is important. These methods are thread safe:
void gwrl_src_add_safely(gwrl * rl, gwrlsrc * src); void gwpr_src_add_safely(gwpr * pr, gwrlsrc_file * src); void gwrl_evt_post_safely(gwrl * rl, gwrlevt * evt); void gwrl_post_function_safely(gwrl * rl, gwrlevt_cb * cb, void * userdata);
With these functions being thread safe, you can add input sources, and post events from different threads safely, at any time.
Because GWRL is thread safe in only these few functions, it means there are some rules you have to follow in order to ensure a consistent internal state for reactors and proactors. The rest of this section describes the rules.
All input sources no matter their type should be owned by a single reactor. If you ever need to switch an input source from one reactor/proactor to another, first remove the input source from the reactor/proactor on the owning thread, then add it to the other reactor/proactor safely with a thread safe function.
All file IO must happen on the same thread.
Windows deserves special mentioning here. In most Windows examples I've seen, they use Windows IOCP for high-performance, but they use a one-to-many model where there's only one completion port, and many threads that perform file IO.
In this scenario the threads have to be synchronized at all times because reads and writes can happen from any thread that the kernel lets run. The examples I've seen go to extensive lengths with locks, and packet sequence mechanisms to ensure the correct ordering of writes. This model is not supported at all and is not recommended. For a recommended file IO model see the Worker Threads section below.
Anytime you create custom events to post, you must post the event to the reactor belonging to the current thread.
If each thread has it's own reactor or proactor, then it's probably a good idea to use thread specific data to store them and retrieve them at any time - unless of course your program is in one file.
Using thread specific data makes it simpler to write larger programs that need access to the reactor or proactor associated with the current thread.
Pthread Example:
#include "gwrl/proactor.h"
#include <pthread.h>
pthread_t th1;
pthread_key_t th1key;
typedef struct thdata {
gwrl * rl;
gwpr * pr;
} thdata;
void stdin_read(gwpr * pr, gwpr_io_info * info) {
printf("did read!\n");
gwpr_buf_free(pr,info->buf);
thdata * data = (thdata *)pthread_getspecific(th1key);
gwrl * rl = data->rl;
gwrl_stop(rl);
}
void testThreadSpecificData() {
thdata * data = (thdata *)pthread_getspecific(th1key);
gwpr * pr = data->pr;
gwrlsrc_file * fsrc = gwpr_set_fd(pr,STDIN_FILENO,NULL);
gwpr_set_cb(pr,fsrc,gwpr_did_read_cb_id,&stdin_read);
gwpr_read(pr,fsrc, gwpr_buf_get(pr,128));
}
void setupReactor(gwrl * rl, gwrlevt * evt) {
testThreadSpecificData();
}
void teardown_reactor(gwrl * rl) {
gwrlsrc * src = NULL;
gwrlsrc * hsrc = NULL;
gwrl_free(rl,&hsrc);
src = hsrc;
while(src) {
if(src->type == GWRL_SRC_TYPE_FILE) close(_gwrlsrcf(src)->fd);
src = src->next;
}
gwrl_free(NULL,&hsrc);
}
void * threadMain(void * arg) {
gwrl * rl = gwrl_create();
gwpr * pr = gwpr_create(rl);
thdata * data = malloc(sizeof(thdata));
data->rl = rl;
data->pr = pr;
pthread_key_create(&th1key,NULL);
pthread_setspecific(th1key,data);
gwrl_post_function(rl,&setupReactor,NULL);
gwrl_run(rl);
teardown_reactor(rl);
return NULL;
}
int main(int argc, char ** argv) {
pthread_create(&th1,NULL,&threadMain,NULL);
pthread_join(th1,NULL);
return 0;
}
If you're going to be writing worker threads the recommended way is to create a reactor/proactor for each thread. An easy example is a high-performance server. For each new client that's accepted, you'd create a new file input source and add it to the reactor of one of your worker threads. The main thread would do all the accepting/connecting, but then delegate the business logic to your worker threads.
This flowchart diagram should help illustrate it better.
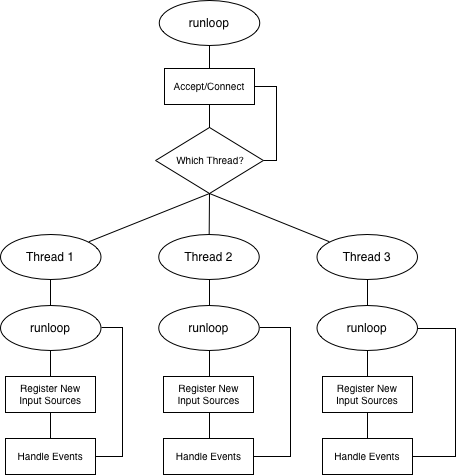
Example:
gwrl * rlthread2;
gwpr * prthread2;
void did_read(gwpr * pr, gwpr_io_info * info) {
printf("IO happened on thread 2!\n");
}
void newly_accepted_src(gwpr * pr, gwrlevt * evt) {
gwpr_set_cb(pr,(gwrlsrc_file *)evt->src,gwpr_did_read_cb_id,&did_read);
gwpr_read(pr,(gwrlsrc_file *)evt->src,gwprbuf_get(prthread2,128));
}
void did_accept(gwpr * pr, gwpr_io_info * info) {
gwprsrc_file * peersrc = info->peersrc;
gwpr_add_src_safe(prthread2,peersrc,&newly_accepted_src);
}
void * thread2(void * arg) {
rlthread2 = gwrl_create();
prthread2 = gwpr_create(rlthread2);
gwrl_run(rlthread2);
return NULL;
}
int main(int argc, char ** argv) {
gwrl * rl = gwrl_create();
gwpr * pr = gwpr_create(rl);
//start thread 2
//sockid_t s = setup socket
gwrlsrc_file * src = gwpr_set_fd(pr,s,NULL);
gwpr_set_cb(pr,src,gwpr_accept_cb_id,&did_accept);
gwpr_accept(pr,src);
gwrl_run(rl);
}
GWRL defines a couple types that you might find useful.
#if defined(PLATFORM_WINDOWS)
typedef HANDLE fileid_t
#else
typedef int fileid_t
#endif
#if defined(PLATFORM_WINDOWS)
typedef SOCKET sockid_t
#else
typedef int sockid_t
#endif
GWRL contains a few socket utility functions that are useful.
The skctl (socket control) function is a socket setup function that can call most of the socket functions you'll ever need like getaddrinfo, socket, listen, bind, etc. You setup a structure to indicate what you'd like the skctl function to do on your behalf, call skctl, and inspect the results.
TCP Server Example:
#include "gwrl/socket.h"
int main(int argc, char ** argv) {
skctlinfo info;
info.node = "0";
info.service = "80";
info.hints.ai_family = AF_UNSPEC;
info.hints.ai_flags = AI_PASSIVE;
info.hints.ai_protocol = IPPROTO_TCP;
info.hints.ai_socktype = SOCKSTREAM;
info.flags = SKCTL_TCP_SERVER;
if((skctl(&info) < 0)) exit(-1);
//continue using info.sockfd
skctlinfo_free(&info,false);
}
UDP Server Example:
#include "gwrl/socket.h"
int main(int argc, char ** argv) {
skctlinfo info;
info.node = 0;
info.service = "13008";
info.hints.ai_family = AF_UNSPEC;
info.hints.ai_flags = AI_PASSIVE;
info.hints.ai_protocol = IPPROTO_UDP;
info.hints.ai_socktype = SOCKDGRAM;
info.flags = SKCTL_UDP_SERVER;
if((skctl(&info) < 0)) exit(-1);
//continue using info.sockfd
skctlinfo_free(&info,false);
}
The socket control function uses bitwise flags to indicate what you'd like the function to do on your behalf. Any one of these flags can be or'd together to control what skctl does internally. Those flags are descibed here.
Call getaddrinfo();
Call socket();
Call connect();
call bind();
Call listen();
Set the SO_REUSEADDR socket option.
Print the final address used by getaddrinfo.
Set the O_NONBLOCK file descriptor option.
(SKCTL_GETADDRINFO|SKCTL_SOCKET|SKCTL_CONNECT)
(SKCTL_GETADDRINFO|SKCTL_SOCKET|SKCTL_CONNECT)
(SKCTL_GETADDRINFO|SKCTL_SOCKET)
(SKCTL_GETADDRINFO|SKCTL_SOCKET|SKCTL_BIND|SKCTL_LISTEN|SKCTL_REUSE_ADDR)
(SKCTL_GETADDRINFO|SKCTL_SOCKET|SKCTL_BIND|SKCTL_REUSE_ADDR)
GWRL contains a few time utility functions you might want to use. Because the event polling functions vary between struct timeval and struct timespec, GWRL uses struct timespec at all times and provides conversion and utility functions.
No details other than their function prototypes will be listed:
void gwtm_ms_to_timeval(int64_t ms, struct timeval * tv); void gwtm_ms_to_timespec(int64_t ms, struct timespec * ts); void gwtm_timeval_to_ms(struct timeval * tv, int64_t * ms); void gwtm_timespec_to_ms(struct timespec * ts, int64_t * ms); void gwtm_add_ms_to_timeval(int64_t ms, struct timeval * tv); void gwtm_add_ms_to_timespec(int64_t ms, struct timespec * ts); void gwtm_gettimeofday_timespec(struct timespec * ts); void gwtm_timeval_to_timespec(struct timeval * tv, struct timespec * ts); void gwtm_timespec_to_timeval(struct timespec * ts, struct timeval * tv); void gwtm_timespec_sub_into(struct timespec * ts1, struct timespec * ts2, struct timespec * into); bool gwtm_timespec_is_expired(struct timespec * ts1); bool gwtm_timespec_copy_if_smaller(struct timespec * source, struct timespec * update); struct timespec * gwtm_timespec_cmp(struct timespec * ts1, struct timespec * ts2);